Это вторая статья в цикле «Что скрывает MAX»
В первой статье я разобрал как MAX собирает ваш IP, определяет VPN и какие сайты из вашей сети. Как MAX помогает РКН строить железный занавес: VPN-детект, сбор IP и проверки на Госуслуги
Дальше — про звонки. В MAX встроена система распознавания ключевых слов (KWS — Keyword Spotting). Нейросеть, которая прогоняет аудио с микрофона прямо во время разговора.
Сразу важное: это не кликбейт
Я не утверждаю, что MAX прямо сейчас слушает ваши разговоры в поисках слов вроде «Путин», «митинг» или «VPN». Текущая модель распознавания обучена только на фразу «не слышу» — по задумке это для определения плохой связи. Прямо сейчас функция выключена на сервере.
Но….я разобрал архитектуру, проследил весь код от микрофона до отправки на сервер — и вот что важно:
-
VK может подменить нейронку на любую другую когда захочет (будет проверка на новые слова)
-
Замена происходит без обновления приложения — достаточно изменить один URL в серверном конфиге или обновить уже существующую (Приложение само подтянет новый набор слов)
-
При срабатывании — результат улетает на сервер VK
-
Пользователь ни о чём не знает, согласие никто не спрашивает
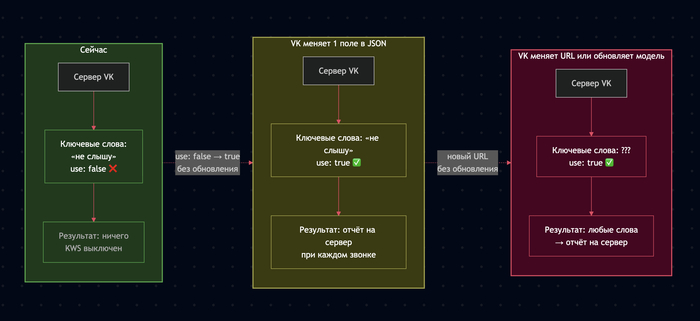
TL;DR
-
Во время звонков в MAX работает система распознавания ключевых слов (KWS) на базе нейросети BC-ResNet
-
Она подтягивается с серверов VK, работает на устройстве внутри WebRTC (технология для звонков)
-
Сейчас модель обучена на фразу «не слышу» и выключена сервером («use»: false)
-
VK может: включить KWS одной настройкой и поменять список слов на проверку, сделать это для конкретного пользователя — без обновления приложения и без уведомления
-
KWS работает только во время звонков, не в фоне, не на голосовых сообщениях
-
При срабатывании — автоматический отчёт на сервер VK с уровнем уверенности
Часть 1: Что я нашёл (для всех)
1. Что такое KWS и как это работает
KWS (Keyword Spotting) — распознавание конкретных слов в аудиопотоке. Вы с этим знакомы: «Окей, Google», «Привет, Алиса», «Hey Siri» — всё это KWS.
Принцип простой: нейросеть берёт звук с микрофона, режет на кусочки по 10 миллисекунд и на каждом решает — это ключевое слово или нет?
VK встроил такую штуку прямо в свой модифицированный WebRTC. Нейросеть крутится локально на устройстве и слушает аудио во время звонка.
2. Что делает текущая нейронка
Я скачал модель с серверов VK (https://st.okcdn.ru/static/calls_android/1-0-1/kws_270525.zip), разобрал её архитектуру и запустил.
Текущий функционал:
-
Архитектура: BC-ResNet (Broadcasted Residual Network) — компактная нейросеть для мобильных устройств
-
Режим: streaming — обрабатывает аудио в реальном времени, кусочек за кусочком
-
Задача: ответ да/нет — «это ключевое слово» или «это всё остальное» (тишина, шум, обычная речь)
-
Ключевое слово: «не слышу» (то есть собеседник жалуется, что плохо слышно)
-
Размер: 1.17 МБ, ~300 тысяч параметров
Для звонков это имеет смысл: собеседник говорит «не слышу» — значит со связью проблемы, приложение может это подхватить.
3. Почему это не просто «определение качества связи»
Распознавать «не слышу» — безобидно. А вот как это устроено внутри — уже нет.
Нейронка приходит с сервера. KWS не зашит в код приложения. При запуске приложение получает от сервера конфиг с URL модели, забирает файл и грузит в нейросетевой движок. Сервер VK решает:
-
Какую нейронку загружать (URL файла)
-
Включена ли KWS вообще (флаг use)
-
Сколько времени слушать (таймер turn_off_in_ms, сейчас 60 секунд)
VK может подменить модель хоть завтра — на любые другие слова. Обновлять приложение не нужно. Спрашивать пользователя — тоже.
Приложение не проверяет, что именно нейронка распознаёт. Если завтра VK положит на CDN модель, обученную на слово «протест» — приложение скачает её и запустит точно так же.
А что в политике конфиденциальности? Я проверил оба документа — Политику конфиденциальности (legal.max.ru/pp) и Пользовательское соглашение (legal.max.ru/ps). Упоминания KWS или анализа аудио во время звонков — ноль.
При этом в Пользовательском соглашении есть описание того, как голосовые и видеосообщения переводятся в текст.
4. Что происходит при срабатывании
Когда нейронка считает, что услышала ключевое слово, происходит следующее:
-
Выдаёт уровень уверенности (число от 0 до 1)
-
Приложение берёт максимальное значение за сессию
-
Приложение формирует отчёт и отправляет на сервер VK (api.ok.ru/api/log/externalLog) через канал vchat.clientStats
VK видит: в таком-то звонке у такого-то пользователя сработал детектор, уверенность такая-то. Всё привязано к userId как и call_id (vchat.clientStats отправляется в привязке к конкретной VoIP-сессии)
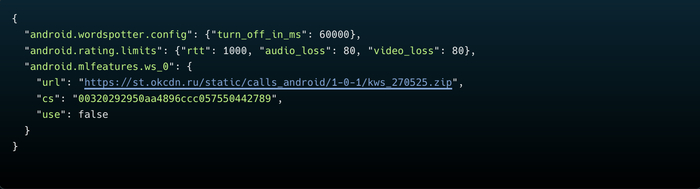
5. Серверный конфиг: то что я перехватил
Во время анализа я перехватил реальный ответ сервера VK с конфигурацией KWS. Вот что сервер присылает приложению:
-
URL модели: https://st.okcdn.ru/static/calls_android/1-0-1/kws_270525.zip
-
MD5: 00320292950aa4896ccc057550442789
-
Включено: НЕТ («use»: false)
-
Таймаут: 60 секунд на звонок
Я забрал модель по этому URL — без авторизации, без cookies. Любой может это сделать прямо сейчас. MD5 совпадает с тем, что прислал сервер.
Ещё я побрутил CDN в поисках других моделей — перебрал 200+ вариантов путей. Нашёл только одну модель в трёх версиях SDK (1-0-1, 1-0-2, 1-0-3) — все три идентичны (одинаковый MD5). На данный момент VK использует только одну модель для фразы «не слышу».
6. Чего KWS не делает (чтобы не нагнетать)
Работает только во время звонков — закрыли приложение, и всё. Кода для фоновой работы KWS я не нашёл.
С голосовыми сообщениями не связан — те переводятся с аудио в текст на серверах VK, это другой процесс, другой код.
Сейчас выключен (use: false). Нейронка уже на устройствах, но не запущена. И ищет она только «не слышу», а не что-то «опасное».
7. Что ещё я нашёл про звонки
KWS — не единственная интересная вещь в работе звонков MAX:
Все звонки идут через сервер VK. P2P-соединений я не увидел — все медиаданные проходят через TURN-сервер VK. Шифрование DTLS-SRTP есть, но от вас до сервера, не от вас до собеседника. На relay-сервере шифрование заканчивается — ключи у VK.
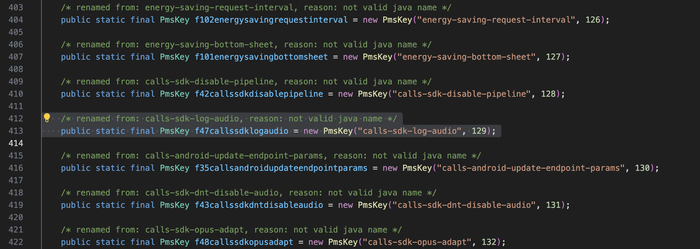
Флаг записи аудио. В коде есть PMS-ключ calls-sdk-log-audio — если VK его включит, аудио звонка пишется в файл. Управляется с сервера.
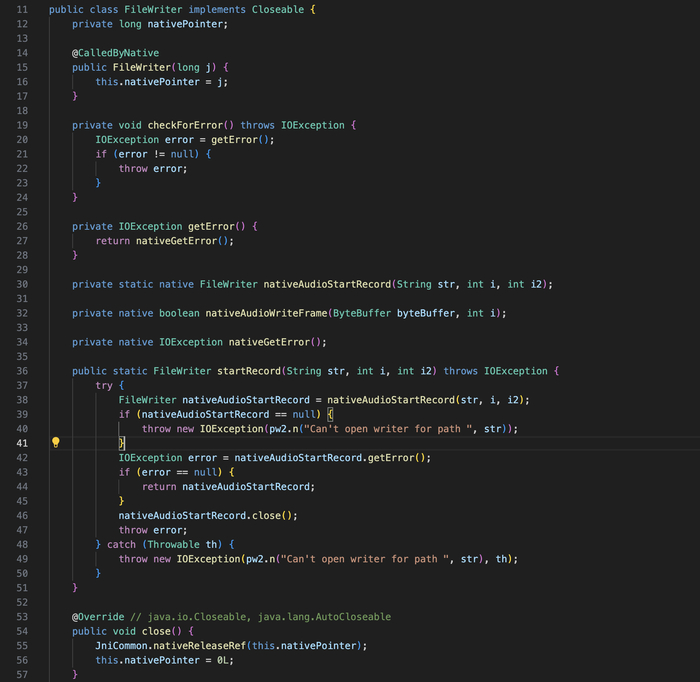
Модифицированный WebRTC. VK не использует стандартный WebRTC — они его модифицировали. В модификации добавлены: нативная запись аудио в Opus (nativeAudioStartRecord, nativeAudioWriteFrame), KWS-интеграция, и кастомные параметры.
Часть 2: Доказательства (для тех, кто хочет проверить)
Ниже — код, конфиги и результаты реверс-инжиниринга. Версия APK 26.12.1 (6679).
2.1 Где живёт KWS в коде
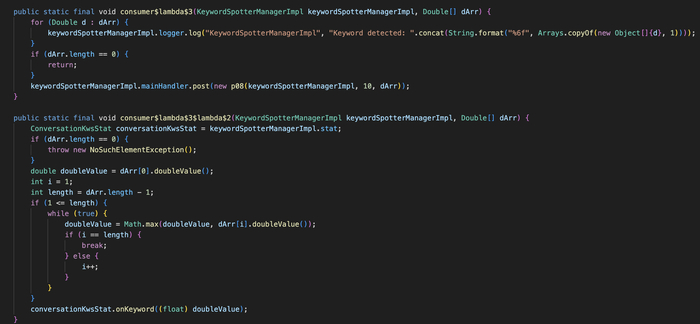
KWS встроен в модифицированный WebRTC внутри нативной библиотеки libjingle_peerconnection_so.so. Точка входа — JNI-метод:
Java_org_webrtc_PeerConnectionFactory_nativeSetKeywordSpotterParams
Это вызов из Java в нативный код. Принимает два параметра: isEnabled (включить/выключить) и filePath (путь к модели на устройстве).
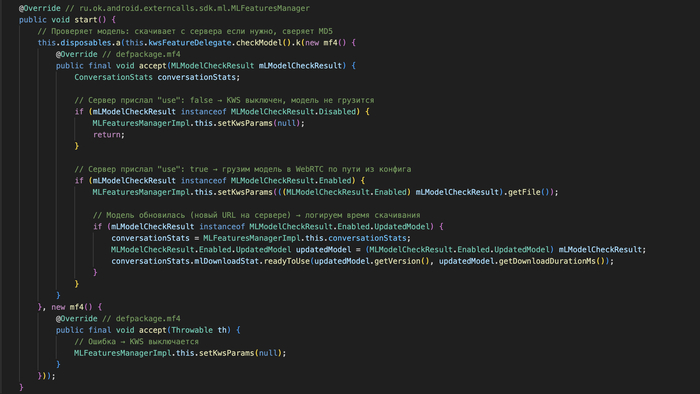
Полная цепочка от сервера до нейросети:
-
Сервер присылает RemoteSettings с конфигом KWS
-
MLFeaturesManagerImpl забирает модель по URL, проверяет MD5
-
KwsFeatureDelegate вызывает setKeywordSpotterParams(isEnabled, filePath)
-
PeerConnectionFactory передаёт параметры в нативный WebRTC
-
kws_impl.cc загружает TFLite-модель
-
BCResNetKWS::computeProbs() (в libEnhancementLibShared.so) обрабатывает аудио
-
KwsBufferizator буферизует фреймы и передаёт через NativeDoubleArrayConsumer
-
KeywordSpotterManagerImpl получает уровень уверенности, берёт максимум
-
ConversationKwsStat.onKeyword(maxConfidence) формирует отчёт
-
Отчёт уходит через vchat.clientStats на серверы VK
Пакет: ru.ok.android.externcalls.sdk.audio — это SDK звонков.
2.2 Архитектура модели
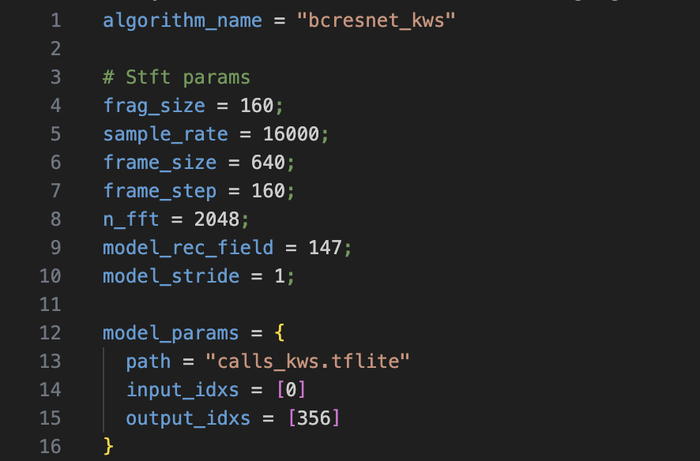
Файл: calls_kws.tflite из kws_270525.zip
-
Вход: [1, 1, 40] — 1 фрейм × 40 мел-частотны
-
Выход: [1, 1, 2] — бинарный softmax: [P(фон), P(ключевое_слово)]
-
Архитектура: BC-ResNet (Broadcasted Residual Network), streaming mode
-
384 тензора, ~1.17 МБ
-
Конфиг: algorithm_name = «bcresnet_kws», sample_rate = 16000
Результаты запуска модели на тестовых данных:
-
Тишина: P(keyword) стремится к 0.0000 после ~40 фреймов тишины
-
Случайный шум: P(keyword) = 0.0000 — ложных срабатываний нет
-
Модель уверенно отличает целевую фразу от всего остального
2.3 Полный flow сетевых запросов
Вот полная карта: какие серверы участвуют, какие запросы идут и в каком формате.
Шаг 1 — Получение конфига (при подключении к серверу):
-
Откуда: api.oneme.ru:443 (постоянное TCP-соединение, MsgPack wire-протокол)
-
Что: RemoteSettings — серверный конфиг со всеми фичами, включая KWS
-
Формат: MsgPack binary → расшифровывается в JSON
-
Ключи KWS в ответе:
«android.wordspotter.config» → {«turn_off_in_ms»: 60000}
«android.mlfeatures.ws_0″ → {«url»: «https://st.okcdn.ru/static/calls_android/1-0-1/kws_270525.zi…«, «cs»: «00320292950aa4896ccc057550442789», «use»: false}
Шаг 2 — Скачивание модели (при первом запуске или обновлении URL):
-
Откуда: st.okcdn.ru (CDN VK, HTTP GET)
-
URL: https://st.okcdn.ru/static/calls_android/1-0-1/kws_270525.zi…
-
Авторизация: никакой — публичный доступ
-
Формат: ZIP-архив (828 КБ) → внутри calls_kws.tflite (TFLite-модель, 1.17 МБ) + config.cfg
-
Проверка: MD5 скачанного файла сравнивается с cs из конфига
-
Сохраняется: {filesDir}/ml_features/ws/calls_kws.tflite + config.cfg
Шаг 3 — Работа KWS (во время звонка, если use: true):
-
Аудио с микрофона → WebRTC соединение → BCResNetKWS::computeProbs() в libEnhancementLibShared.so
-
Вся обработка на устройстве, в сеть пока ничего не уходит
-
Таймаут: turn_off_in_ms (60 секунд) — после этого KWS останавливается
Шаг 4 — Отправка результата (после/во время звонка):
-
Куда: api.ok.ru/api/log/externalLog (POST, gzip, session_key)
-
Канал: vchat.clientStats
{«metric»: «bad_call_detected_by_audio_spotter», «string_value»: «не слышу», «double_value»: 0.95} + userId, sessionId, call_id
Медиаданные самого звонка:
-
Куда: 155.212.206.115:43210 (TURN-сервер VK, UDP)
-
Шифрование: DTLS-SRTP (end-to-relay, не end-to-end)
-
Сертификат: QRtpServer 1.1.10
2.4 Отчёт о срабатывании
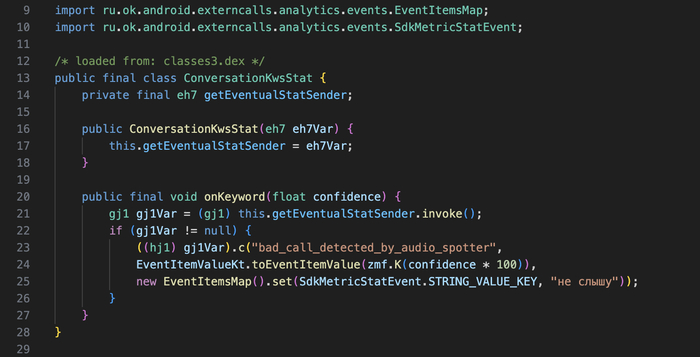
Файл: defpackage/ConversationKwsStat.java
При срабатывании формируется событие:
-
metric: «bad_call_detected_by_audio_spotter»
-
string_value: «не слышу» (захардкожено)
-
double_value: максимальная уверенность за звонок
-
Канал: vchat.clientStats
Имя «не слышу» зашито в код — но модель определяется URL с сервера. Если VK ее заменит, код по-прежнему будет отправлять «не слышу» как строку, даже если реальная модель будет детектить совершенно другую фразу. Или VK обновит и код в следующей версии.
2.5 Модель можно скачать прямо сейчас
Проверяйте сами:
curl -O https://st.okcdn.ru/static/calls_android/1-0-1/kws_270525.zip
-
HTTP 200, 828 КБ
-
Без авторизации, без cookies, без заголовков
-
Внутри ZIP: calls_kws.tflite (модель, 1.17 МБ) + config.cfg
-
MD5 файла: 00320292950aa4896ccc057550442789 — совпадает с серверным конфигом
Содержимое config.cfg:
-
algorithm_name = «bcresnet_kws»
-
sample_rate = 16000
Я проверил три версии SDK на CDN:
-
https://st.okcdn.ru/static/calls_android/1-0-1/kws_270525.zi… — HTTP 200, MD5: 00320292…
-
https://st.okcdn.ru/static/calls_android/1-0-2/kws_270525.zi… — HTTP 200, тот же MD5
-
https://st.okcdn.ru/static/calls_android/1-0-3/kws_270525.zi… — HTTP 200, тот же MD5
Одна и та же модель во всех версиях. Имя файла kws_270525 предполагает дату создания 27.05.2025. Просканировал 200+ вариантов путей — других моделей на CDN не нашёл.
2.6 Почему «модель можно заменить» — не теория
Цепочка замены модели:
-
VK меняет поле url в android.mlfeatures.ws_0 на новый адрес или просто обновляет модель
-
Сервер пушит обновлённый RemoteSettings через постоянное TCP-соединение
-
MLFeaturesManagerImpl видит новый URL, тянет новый ZIP
-
Проверяет MD5 (новый, для нового файла)
-
Распаковывает .tflite + .cfg в ml_features/ws/
-
При следующем звонке KwsFeatureDelegate загружает новую модель
-
BCResNetKWS начинает детектить новые ключевые слова
На стороне приложения нет проверки того, что именно модель распознаёт. Нет whitelist допустимых слов. Нет уведомления пользователя. MD5 проверяет только целостность файла — что скачалось без ошибок.
2.7 Дополнительные аудио-возможности в звонках
Запись аудио через серверный флаг: PMS-ключ calls-sdk-log-audio (key 129) может включить запись аудио звонка в файл. Плюс JNI-методы nativeStartAecDump / nativeStopAecDump позволяют дампить raw-аудио в файловый дескриптор. Всё управляется сервером.
Все звонки через relay VK: Все медиаданные идут через TURN-сервер VK (155.212.206.115:43210). Шифрование DTLS-SRTP — от вас до сервера, не от вас до собеседника. Сертификат сервера: QRtpServer 1.1.10.
Типы ML-фич в конфиге:
-
WS (WordSpotter) — распознавание ключевых слов ← то, что мы разобрали
-
NS (Noise Suppression) — подавление шума
MLFeaturesManagerImpl поддерживает несколько типов моделей. Сейчас WS и NS, но подцепить новый тип — дело пары строк.
Выводы
Если вы дочитали до сюда — вы уже поняли суть.
Скажу одно: разница между «детектором плохой связи» и «детектором произвольных слов» — это один URL в JSON-конфиге. Модель, код, процесс отправки на сервер — всё одно и то же. Меняется только файл на CDN.
Я не знаю, планирует ли VK это использовать иначе. Но я знаю, что в политике конфиденциальности об этом ни слова, согласие не спрашивается, а модель можно скачать и проверить прямо сейчас. Ссылка выше.
Код — вот он. Модель — в открытом доступе. Проверяйте.